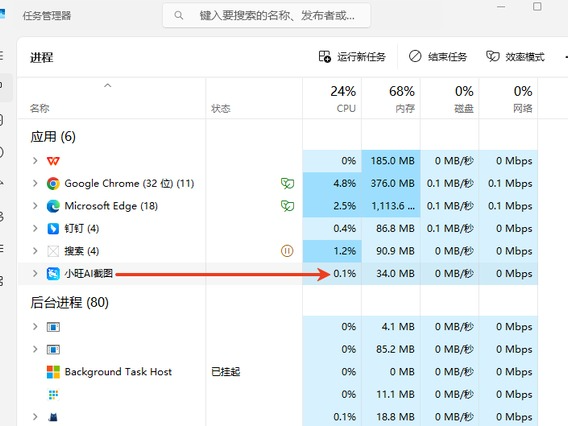
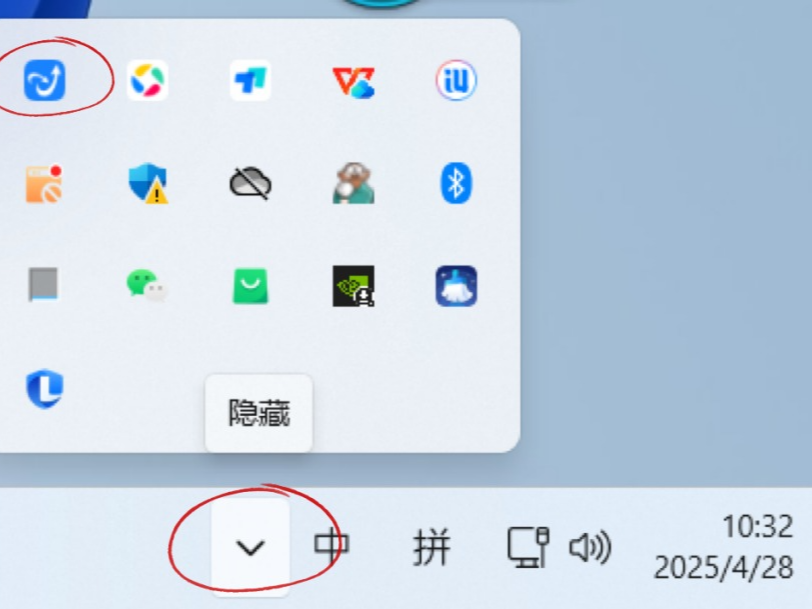
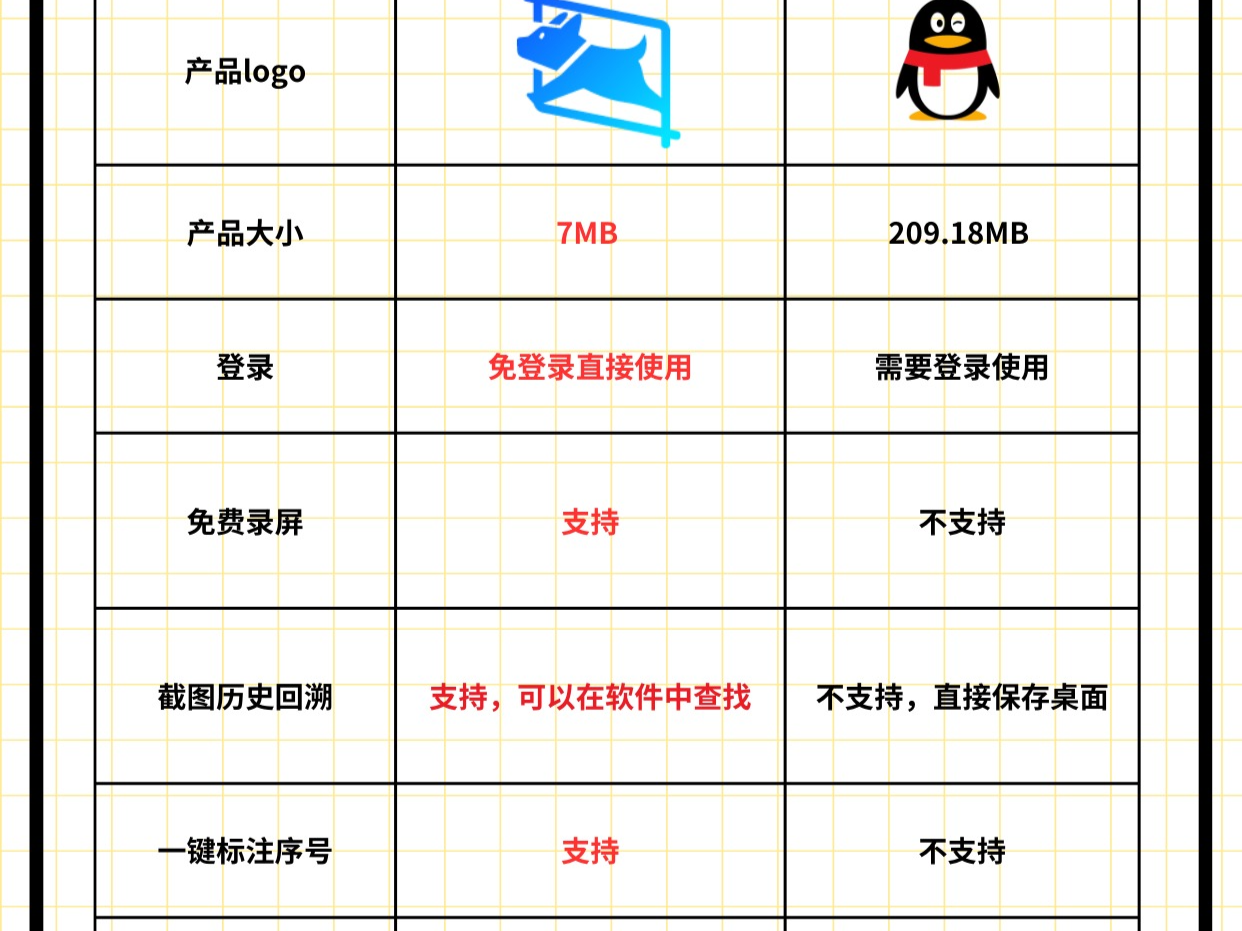
表情
表情


|
世界上的各地区都有本地的语言。地区差异直接导致了语言环境的差异。在开发一个国际化程序的过程中,处理语言问题就显得很重要了。 这是一个世界范围内都存在的问题,所以,Java提供了世界性的解决方法。本文描述的方法是用于处理中文的,但是,推而广之,对于处理世界上其它国家和地区的语言同样适用。 汉字是双字节的。所谓双字节是指一个双字要占用两个BYTE的位置(即16位),分别称为高位和低位。中国规定的汉字编码为GB2312,这是强制性的,目前几乎所有的能处理中文的应用程序都支持GB2312。GB2312包括了一二级汉字和9区符号,高位从0xa1到0xfe,低位也是从0xa1到0xfe,其中,汉字的编码范围为0xb0a1到0xf7fe。 另外有一种编码,叫做GBK,但这是一份规范,不是强制的。GBK提供了20902个汉字,它兼容GB2312,编码范围为0x8140到0xfefe。GBK中的所有字符都可以一一映射到Unicode 2.0。 在不久的将来,中国会颁布另一种标准:GB18030-2000(GBK2K)。它收录了藏、蒙等少数民族的字型,从根本上解决了字位不足的问题。注意:它不再是定长的。其二字节部份与GBK兼容,四字节部分是扩充的字符、字形。它的首字节和第三字节从0x81到0xfe,二字节和第四字节从0x30到0x39。 本文不打算介绍Unicode,有兴趣的可以浏览“http://www.unicode.org/”查看更多的信息。Unicode有一个特性:它包括了世界上所有的字符字形。所以,各个地区的语言都可以建立与Unicode的映射关系,而Java正是利用了这一点以达到异种语言之间的转换。 在JDK中,与中文相关的编码有: 表1 JDK中与中文相关的编码列表 编码名称 说明 在实际编程时,接触得比较多的是GB2312(GBK)和ISO8859-1。 为什么会有“?”号 上文说过,异种语言之间的转换是通过Unicode来完成的。假设有两种不同的语言A和B,转换的步骤为:先把A转化为Unicode,再把Unicode转化为B。 举例说明。有GB2312中有一个汉字“李”,其编码为“C0EE”,欲转化为ISO8859-1编码。步骤为:先把“李”字转化为Unicode,得到“674E”,再把“674E”转化为ISO8859-1字符。当然,这个映射不会成功,因为ISO8859-1中根本就没有与“674E”对应的字符。 当映射不成功时,问题就发生了!当从某语言向Unicode转化时,如果在某语言中没有该字符,得到的将是Unicode的代码“\uffffd”(“\u”表示是Unicode编码,)。而从Unicode向某语言转化时,如果某语言没有对应的字符,则得到的是“0x3f”(“?”)。这就是“?”的由来。 例如:把字符流buf =“0x80 0x40 0xb0 0xa1”进行new String(buf, "gb2312")操作,得到的结果是“\ufffd\u554a”,再println出来,得到的结果将是“?啊”,因为“0x80 0x40”是GBK中的字符,在GB2312中没有。 再如,把字符串String="\u00d6\u00ec\u00e9\u0046\u00bb\u00f9"进行new String (buf.getBytes("GBK"))操作,得到的结果是“3fa8aca8a6463fa8b4”,其中,“\u00d6”在“GBK”中没有对应的字符,得到“3f”,“\u00ec”对应着“a8ac”,“\u00e9”对应着“a8a6”,“0046”对应着“46”(因为这是ASCII字符),“\u00bb”没找到,得到“3f”,最后,“\u00f9”对应着“a8b4”。把这个字符串println一下,得到的结果是“?ìéF?ù”。看到没?这里并不全是问号,因为GBK与Unicode映射的内容中除了汉字外还有字符,本例就是最好的明证。 所以,在汉字转码时,如果发生错乱,得到的不一定都是问号噢!不过,错了终究是错了,50步和100步并没有质的差别。 或者会问:如果源字符集中有,而Unicode中没有,结果会如何?回答是不知道。因为我手头没有能做这个测试的源字符集。但有一点是肯定的,那就是源字符集不够规范。在Java中,如果发生这种情况,是会抛出异常的。
|
正在阅读:深入剖析JSP和Servlet对中文的处理深入剖析JSP和Servlet对中文的处理
2008-02-27 09:18
出处:PConline原创
责任编辑:chenzhenjia

键盘也能翻页,试试“← →”键
| 本文导航 | ||
|
 西门子(SIEMENS)274升大容量家用三门冰箱 混冷无霜 零度保鲜 独立三循环 玻璃面板 支持国家补贴 KG28US221C
5399元
西门子(SIEMENS)274升大容量家用三门冰箱 混冷无霜 零度保鲜 独立三循环 玻璃面板 支持国家补贴 KG28US221C
5399元 苏泊尔电饭煲家用3-4-5-8个人4升电饭锅多功能一体家用蓝钻圆厚釜可做锅巴饭煲仔饭智能煮粥锅预约蒸米饭 不粘厚釜 4L 5-6人可用
329元
苏泊尔电饭煲家用3-4-5-8个人4升电饭锅多功能一体家用蓝钻圆厚釜可做锅巴饭煲仔饭智能煮粥锅预约蒸米饭 不粘厚釜 4L 5-6人可用
329元 绿联65W氮化镓充电器套装兼容45W苹果16pd多口Type-C快充头三星华为手机MacbookPro联想笔记本电脑配线
99元
绿联65W氮化镓充电器套装兼容45W苹果16pd多口Type-C快充头三星华为手机MacbookPro联想笔记本电脑配线
99元 KZ Castor双子座有线耳机入耳式双单元哈曼曲线发烧HiFi耳返耳麦
88元
KZ Castor双子座有线耳机入耳式双单元哈曼曲线发烧HiFi耳返耳麦
88元 格兰仕(Galanz)电烤箱 家用 40L大容量 上下独立控温 多层烤位 机械操控 烘培炉灯多功能 K42 经典黑 40L 黑色
499元
格兰仕(Galanz)电烤箱 家用 40L大容量 上下独立控温 多层烤位 机械操控 烘培炉灯多功能 K42 经典黑 40L 黑色
499元 漫步者(EDIFIER)M25 一体式电脑音响 家用桌面台式机笔记本音箱 蓝牙5.3 黑色 520情人节礼物
109元
漫步者(EDIFIER)M25 一体式电脑音响 家用桌面台式机笔记本音箱 蓝牙5.3 黑色 520情人节礼物
109元 修改头像
修改头像