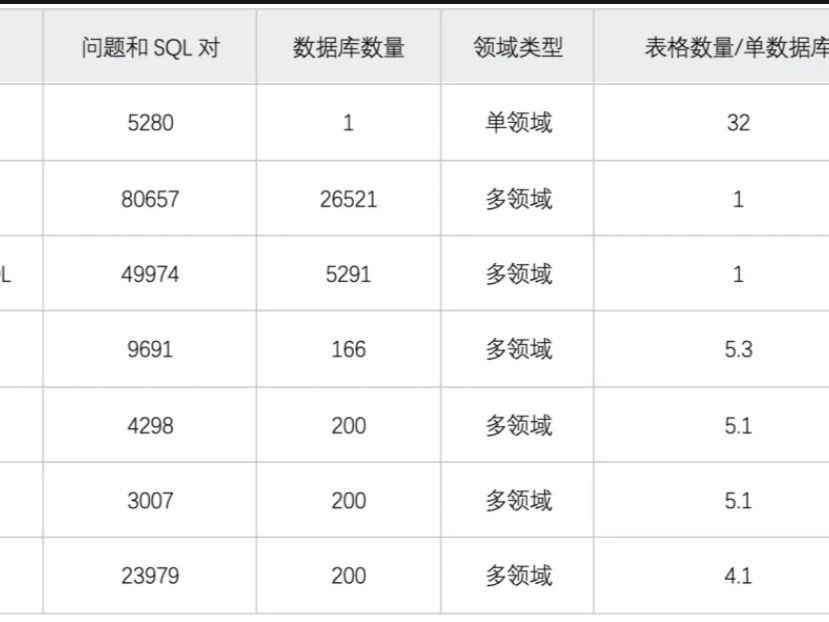
这个例子的输出如下所示:
| Group1=[abra]
Capture0=[abracad] Index=0 Length=7
Capture1=[abra] Index=7 Length=4
Group2=[cad]
Capture0=[cad] Index=4 Length=3
Group1=[abra]
Capture0=[abracad] Index=12 Length=7
Capture1=[abra] Index=19 Length=4
Group2=[cad]
Capture0=[cad] Index=16 Length=3
Group1=[abra]
Capture0=[abracad] Index=24 Length=7
Capture1=[abra] Index=31 Length=4
Group2=[cad]
Capture0=[cad] Index=28 Length=3 |
我们首先从考查字符串pat开始,pat中包含有表达式。第一个capture是从第一个圆括号开始的,然后表达式将匹配到一个abra。第二个capture组从第二个圆括号开始,但第一个capture组还没有结束,这意味着第一个组匹配的结果是abracad ,而第二个组的匹配结果仅仅是cad。因此如果通过使用?符号而使cad成为一项可选的匹配,匹配的结果就可能是abra或abracad。然后,第一个组就会结束,通过指定+符号要求表达式进行多次匹配。
现在我们来看看匹配过程中发生的情况。首先,通过调用Regex的constructor方法建立表达式的一个实例,并在其中指定各种选项。在这个例子中,由于在表达式中有注释,因此选用了x选项,另外还使用了一些空格。打开x选项,表达式将会忽略注释和其中没有转义的空格。
然后,取得表达式中定义的组的编号的清单。你当然可以显性地使用这些编号,在这里使用的是编程的方法。如果使用了命名的组,作为一种建立快速索引的途径这种方法也十分有效。
接下来是完成第一次匹配。通过一个循环测试当前的匹配是否成功,接下来是从group 1开始重复对组清单执行这一操作。在这个例子中没有使用group 0的原因是group 0是一个完全匹配的字符串,如果要通过收集全部匹配的字符串作为一个单一的字符串,就会用到group 0了。
我们跟踪每个group中的CaptureCollection。通常情况下每次匹配、每个group中只能有一个capture,但本例中的Group1则有两个capture:Capture0和Capture1。如果你仅需要Group1的ToString,就会只得到abra,当然它也会与abracad匹配。组中ToString的值就是其CaptureCollection中最后一个Capture的值,这正是我们所需要的。如果你希望整个过程在匹配abra后结束,就应该从表达式中删除+符号,让regex引擎知道我们只需要对表达式进行匹配。
|
 表情
表情