|
ЎЎЎЎФӨұёЦӘК¶Јә ЎЎЎЎ1.ЧЦҪЪәНunicode
ЎЎЎЎИз№ыДгІ»Цё¶ЁconverterЈ¬ФтПөНі»бЧФ¶ҜК№УГөұЗ°өДEncodingЈ¬GBЖҪМЁЙПУГGBKЈ¬ENЖҪМЁЙПУГ8859_1 ЎЎЎЎ ЎЎЎЎОТГЗАҙҫНТ»ёцјтөҘөДАэЧУЈә ЎЎЎЎ"Дг"өДgbВлКЗЈә0xC4E3 Ј¬unicodeКЗ0x4F60 ЎЎЎЎДгУГ:
ЎЎЎЎҙтУЎіцАҙКЗ0x4F60 ЎЎЎЎө«КЗИз№ыК№УГ8859_1өДұаВлЈ¬ҙтУЎіцАҙКЗ ЎЎЎЎ0x00C4Ј¬0x00E3 ЎЎЎЎАэЈұ ЎЎЎЎ·ҙ№эАҙЈә
ЎЎЎЎҙтУЎіцАҙКЗЈә0xC4Ј¬0xE3 ЎЎЎЎАэЈІ ЎЎЎЎИз№ыУГ8859_1ҫНКЗ0x3FЈ¬?әЕЈ¬ұнКҫОЮ·ЁЧӘ»ҜЎЎЎЎЎЎЎЎЎЎ ЎЎЎЎәЬ¶аЦРОДОКМвҫНКЗҙУХвБҪёцЧојтөҘөДАаЕЙЙъіцАҙөДЎЈ¶шИҙУРәЬ¶аАаІ»ЦұҪУЦ§іЦ°СEncodingКдИлЈ¬ХвёшОТГЗҙшАҙЦо¶аІ»ұгЎЈәЬ¶аіМРтДСөГУГencodingБЛЈ¬ЦұҪУУГdefaultөДencodingЈ¬ХвҫНёшОТГЗТЖЦІҙшАҙБЛәЬ¶аА§ДС ЎЎЎЎ ЎЎЎЎ2.UTF-8 ЎЎЎЎUTF-8КЗәНUnicodeТ»Т»¶ФУҰөДЈ¬ЖдКөПЦәЬјтөҘ ЎЎЎЎ ЎЎЎЎ7О»өДUnicode: 0 _ _ _ _ _ _ _ ЎЎЎЎ11О»өДUnicode: 1 1 0 _ _ _ _ _ 1 0 _ _ _ _ _ _ ЎЎЎЎ16О»өДUnicode: 1 1 1 0 _ _ _ _ 1 0 _ _ _ _ _ _ 1 0 _ _ _ _ _ _ ЎЎЎЎ21О»өДUnicode: 1 1 1 1 0 _ _ _ 1 0 _ _ _ _ _ _ 1 0 _ _ _ _ _ _ 1 0 _ _ _ _ _ _ ЎЎЎЎҙу¶аКэЗйҝцКЗЦ»К№УГөҪ16О»ТФПВөДUnicode: ЎЎЎЎДг"өДgbВлКЗЈә0xC4E3 Ј¬unicodeКЗ0x4F60 ЎЎЎЎОТГЗ»№КЗУГЙПГжөДАэЧУ ЎЎЎЎАэЈұЈә0xC4E3өД¶юҪшЦЖЈә ЎЎЎЎ1 1 0 0 0 1 0 0 1 1 1 0 0 0 1 1 ЎЎЎЎУЙУЪЦ»УРБҪО»ОТГЗ°ҙХХБҪО»өДұаВлАҙЕЕЈ¬ө«КЗОТГЗ·ўПЦХвРРІ»НЁЈ¬ ЎЎЎЎТтОӘөЪЈ·О»І»КЗ0ТтҙЛЈ¬·ө»Ш"?"
|
ХэФЪФД¶БЈәJavaЦРОДОКМвПкҪв,өЧІгұаВлҪвЖКJavaЦРОДОКМвПкҪв,өЧІгұаВлҪвЖК
2004-10-29 12:07
іцҙҰЈәPConline
ФрИОұајӯЈәlinjixiong

јьЕМТІДЬ·ӯТіЈ¬КФКФЎ°Ўы ЎъЎұјь
Па№ШОДХВ
ФЪJavaЦРҙҰАнИХЦҫјЗВј
JAVAУЕЦКҙъВлұаРҙөД30МхҝЙРРҪЁТй
javaҝӘ·ў»·ҫіҙоҪЁ·Ҫ·ЁҪйЙЬ
java state ЧҙМ¬ЙијЖДЈКҪ
ұаіМУпСФБчРРЦёКэ¶юФВ°сөҘ·ўІјЈәPythonі¬JavaЙэЦБөЪ1О»
°ІЧҝРЮёДҙуКҰЕдЦГJavaФЛРР»·ҫіҪМіМ ҪМДгҝмЛЩК№УГ
јЧ№ЗОДПтЛчТӘ88ТЪ°ІЧҝПөНіJava°жИЁ·СЈә№ИёиС°ЗуІө»Ш
№ИёиЙПКйГАЧоёЯ·ЁФәЈә¶ФJavaЗЦИЁ°ёЧцЧоЦХІГҫц
Win10ФхГҙЕдЦГJava»·ҫіұдБҝ Java»·ҫіұдБҝЕдЦГҪМіМ


№ШЧўОТГЗ


ИИГЕЕЕРР
-
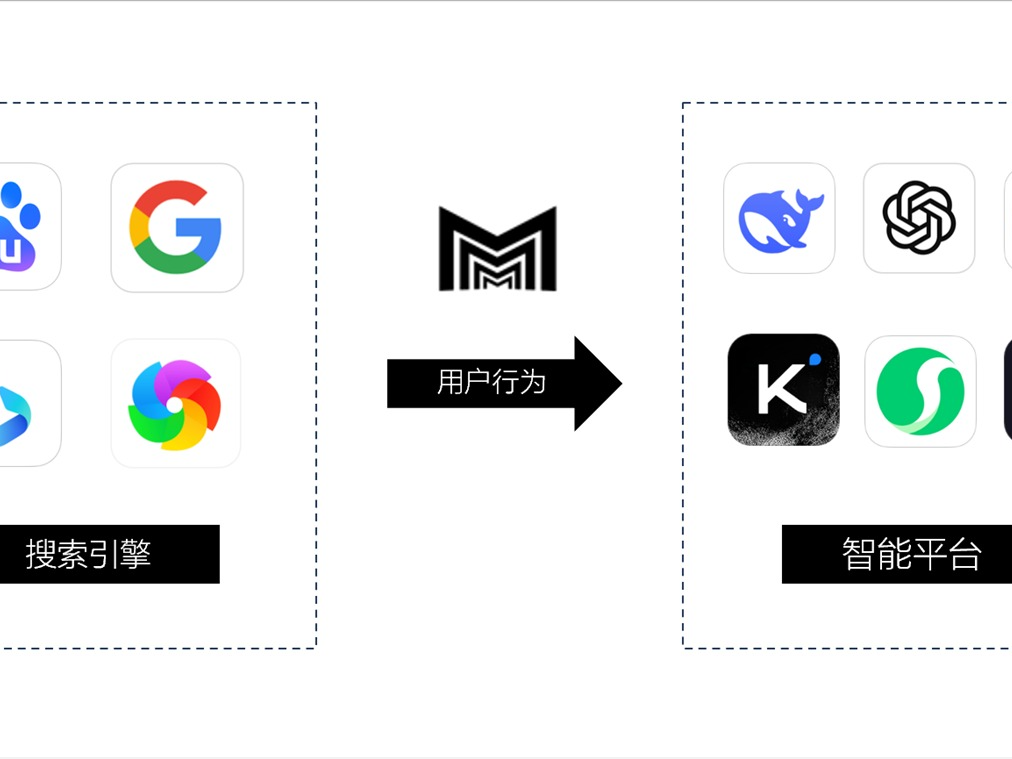 ВцЛЩҝЖјјЈәAiЖҪМЁУЕ»ҜЈЁGEOУЕ»ҜЈ©DeepseekЎўChatGPTЙъіЙКҪРЕПўAIУЕ»ҜІЯВФ
0
ВцЛЩҝЖјјЈәAiЖҪМЁУЕ»ҜЈЁGEOУЕ»ҜЈ©DeepseekЎўChatGPTЙъіЙКҪРЕПўAIУЕ»ҜІЯВФ
0
-
 HarmonyOS 5Йэј¶МеСйЈәёьЦЗДЬЎўёьБчі©Ј¬АПУГ»§·ЕРДЙэј¶ЈЎ
0
HarmonyOS 5Йэј¶МеСйЈәёьЦЗДЬЎўёьБчі©Ј¬АПУГ»§·ЕРДЙэј¶ЈЎ
0
-
 ҙУЎ°Цёјв№Ұ·тЎұөҪЎ°Йъ»оД§·ЁЎұ әиГЙ5КЦКЖІЩЧчИГОТі№өЧЎ°ҪдөфЎұ°ҙЕҘ
0
ҙУЎ°Цёјв№Ұ·тЎұөҪЎ°Йъ»оД§·ЁЎұ әиГЙ5КЦКЖІЩЧчИГОТі№өЧЎ°ҪдөфЎұ°ҙЕҘ
0
-
 №Щ·ҪұіКй|ЕМөг2025ХжКөЎў°ІИ«ЎўҝҝЖЧөДПаЗЧҪ»УСЖҪМЁ
0
№Щ·ҪұіКй|ЕМөг2025ХжКөЎў°ІИ«ЎўҝҝЖЧөДПаЗЧҪ»УСЖҪМЁ
0
-
 °ўАпҝдҝЛЎ°ҪМУэјЖ»®ЎұПЭЙн·ЭИПЦӨ·зІЁЈ¬ФЪ»ӘБфС§ЙъОЮ·ЁБмИЎ»бФұ
0
°ўАпҝдҝЛЎ°ҪМУэјЖ»®ЎұПЭЙн·ЭИПЦӨ·зІЁЈ¬ФЪ»ӘБфС§ЙъОЮ·ЁБмИЎ»бФұ
0
ИИГЕИнјю
УОП·ЧЁЗш





IT°ЩҝЖ
ИИГЕЧЁМв
ЖыіөЧКС¶
ЧоРВЧКС¶АлПЯЛжКұҝҙ
БДМмНВІЫУ®ҪұЖ·